哈夫曼树
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。

基本信息
- 中文名
哈夫曼树
- 外文名
Huffman Tree
- 又名
最优树
- 路径长度
根结点到第L层结点路径长度为L-1
- 带权路径长度
WPL
- 应用
发展历程



1951年,霍夫曼在麻省理工学院(MIT)攻读博士学位,他和修读信息论课程的同学得选择是完成学期报告还是期末考试。导师罗伯特·法诺(Robert Fano)出的学期报告题目是:查找最有效的二进制编码。由于无法证明哪个已有编码是最有效的,霍夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的想法,并很快证明了这个方法是最有效的。霍夫曼使用自底向上的方法构建二叉树,避免了次优算法香农-范诺编码(Shannon–Fano coding)的最大弊端──自顶向下构建树。
1952年,于论文《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)中发表了这个编码方法。
主要内容




在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节,即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
霍夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明霍夫曼树的WPL是最小的。
应用领域
1、哈夫曼编码
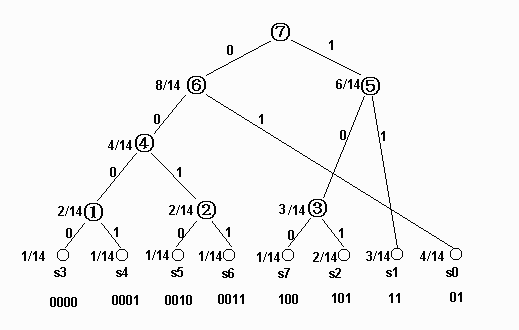
在数据通信中,需要将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。例如,需传送的报文为“AFTER DATA EAR ARE ART AREA”,这里用到的字符集为“A,E,R,T,F,D”,各字母出现的次数为{8,4,5,3,1,1}。现要求为这些字母设计编码。要区别6个字母,最简单的二进制编码方式是等长编码,固定采用3位二进制,可分别用000、001、010、011、100、101对“A,E,R,T,F,D”进行编码发送,当对方接收报文时再按照三位一分进行译码。显然编码的长度取决报文中不同字符的个数。若报文中可能出现26个不同字符,则固定编码长度为5。然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短码,使用频率低的用长码,以优化整个报文编码。




为使不等长编码为前缀编码(即要求一个字符的编码不能是另一个字符编码的前缀),可用字符集中的每个字符作为叶子结点生成一棵编码二叉树,为了获得传送报文的最短长度,可将每个字符的出现频率作为字符结点的权值赋予该结点上,显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码长,频率高编码短,这样就保证了此树的最小带权路径长度效果上就是传送报文的最短长度。因此,求传送报文的最短长度问题转化为求由字符集中的所有字符作为叶子结点,由字符出现频率作为其权值所产生的哈夫曼树的问题。利用哈夫曼树来设计二进制的前缀编码,既满足前缀编码的条件,又保证报文编码总长最短。
哈夫曼静态编码:它对需要编码的数据进行两遍扫描:第一遍统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并必须把树的信息保存起来,即把字符0-255(2^8=256)的频率值以2-4BYTES的长度顺序存储起来,(用4Bytes的长度存储频率值,频率值的表示范围为0--2^32-1,这已足够表示大文件中字符出现的频率了)以便解压时创建同样的哈夫曼树进行解压;第二遍则根据第一遍扫描得到的哈夫曼树进行编码,并把编码后得到的码字存储起来。
哈夫曼动态编码:动态哈夫曼编码使用一棵动态变化的哈夫曼树,对第t+1个字符的编码是根据原始数据中前t个字符得到的哈夫曼树来进行的,编码和解码使用相同的初始哈夫曼树,每处理完一个字符,编码和解码使用相同的方法修改哈夫曼树,所以没有必要为解码而保存哈夫曼树的信息。编码和解码一个字符所需的时间与该字符的编码长度成正比,所以动态哈夫曼编码可实时进行。
2、哈夫曼译码
在通信中,若将字符用哈夫曼编码形式发送出去,对方接收到编码后,将编码还原成字符的过程,称为哈夫曼译码。