强影响点
基本信息
- 中文名
强影响点
- 所属学科
数学
- 所属问题
数理统计
- 相关问题
多重线性回归模型参数估计
- 相关概念
线性回归、异常点、杠杆点等
基本介绍
众所周知,线性回归拟合时使用的是最小二乘法,即保证各实测点至直线纵向距离的平方和为最小,这就带来了一个问题:如果存在异常点或离群值,它们离回归直线较远,相应距离的平方就非常的大,为了保证平方和为最小,回归直线不得不强烈的向该点所在方位偏移,显然,这可能会导致错误的分析结论。因此,在回归分析中必须要仔细考虑有无强影响点存在,在样本量比较小的时候尤其应注意该问题。
强影响点是指保留该点与删除该点2种情况下建立的回归方程中的回归系数会产生很大差异的点。
一般称严重偏离既定模型的数据点为异常点,远离数据主体的点为高杠杆点,对统计推断影响特别大的点为强影响点。其中异常点和高杠杆点都有可能形成强影响点2。
强影响点的诊断
常用的诊断统计量有:
(1)描述性统计量。设投影阵的对角元为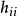 ,的值越大,则第i点对回归系数的估计的影响越大(也称该点为杠杆点);
,的值越大,则第i点对回归系数的估计的影响越大(也称该点为杠杆点);
(2)采用Cook距离。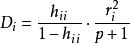 ,式中
,式中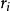 是第i点的标准化残差,该值越大,则第i点对回归系数的估计的影响越大;
是第i点的标准化残差,该值越大,则第i点对回归系数的估计的影响越大;
(3) W-K统计量。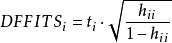 ,式中
,式中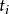 是第i点的外学生化残差,该值越大,则第i点对回归系数的估计的影响越大。
是第i点的外学生化残差,该值越大,则第i点对回归系数的估计的影响越大。
若某点为异常点,它可能是强影响点,但也可能不是强影响点,同样,强影响点可能是异常点,也可能不是。
当具有异常点或强影响点时,避免它对于估计和拟合的影响的一种方法是删除该点后建立回归方程3。
SPSS中对强影响点的诊断有以下几种方法:
1.做出散点图,观察有无离群值,它们往往就是强影响点。需要注意的是有些观察值在各个变量单独描述时处在正常范围内,但几个变量联合描述则为异常,例如年龄10岁和体重70公斤单独存在时都不奇怪,但如果同一个人年龄10岁并且体重70公斤显然就不正常了。
2.使用Statistic子对话框中的残差诊断指标,如果残差非常大,则相应数据离回归直线较远,可能为强影响点。
3.使用Save子对话框中的距离指标和专门的影响力统计量。相应的指标和标准请参见Linear过程的界面说明。
4.采用稳健回归方法。对线性回归模型进行诊断时,如果存在多个异常点,使用以上方法容易发生掩盖现象,即未能识别真正的异常点。此时,我们应该考虑采用基于稳健估计的诊断方法。稳健回归方法本身是为了减少异常值对估计值的扰动,属于诊断后的治疗措施。但同时它也可以作为识别异常点的工具。
对强影响点的处理对策
如果确认存在强影响点,首先应当做的工作是检查原始记录,看看是不是数据录入错误。如果确认数据无误,则分析中可能采取的策略有:
去除:如果只有一两个强影响点,可以考虑将其不纳入分析,以确保分析结果能够代表大多数数据的特征。毕竟统计分析是一个少数服从多数的民主过程,可以在分析报告后对这几个强影响点进行单独描述,以全面概括样本信息。