信源编码定理
在信息论中,香农的信源编码定理(或无噪声编码定理)确立了数据压缩的限度,以及香农熵的操作意义。信源编码定理表明(在极限情况下,随着独立同分布随机变量数据流的长度趋于无穷)不可能把数据压缩得码率(每个符号的比特的平均数)比信源的香农熵还小,不满足的几乎可以肯定,信息将丢失。但是有可能使码率任意接近香农熵,且损失的概率极小。码符号的信源编码定理把码字的最小可能期望长度看作输入字(看作随机变量)的熵和目标编码表的大小的一个函数,给出了此函数的上界和下界。

基本信息
- 中文名
信源编码定理
- 外文名
source coding theorem
- 领域
信息论
- 意义
确立了数据压缩的限度
- 有关术语
香农熵
- 应用
数据压缩
简介
信源编码是从信息源的符号(序列)到码符号集(通常是bit)的映射,使得信源符号可以从二进制位元(无损信源编码)或有一些失真(有损信源编码)中准确恢复。在信息论中,信源编码定理非正式地陈述为:
N 个熵均为 H(X) 的独立同分布的随机变量在 N → ∞ 时,可以很小的信息损失风险压缩成多于 N H(X) bit;但相反地,若压缩到少于 NH(X) bit,则信息几乎一定会丢失。令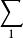 ,
, 表示两个有限编码表,并令
表示两个有限编码表,并令 和
和 (分别)表示来自那些编码表的所有有限字的集合。设 X 为从
(分别)表示来自那些编码表的所有有限字的集合。设 X 为从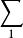 取值的随机变量,令 f 为从到的可译码,其中
取值的随机变量,令 f 为从到的可译码,其中 = a。令 S 表示字长 f (X) 给出的随机变量。
= a。令 S 表示字长 f (X) 给出的随机变量。
如果 f 是对 X 拥有最小期望字长的最佳码,那么(Shannon 1948):
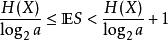
证明
对于 1 ≤ i ≤ n 令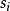 表示每个可能的
表示每个可能的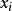 的字长。定义
的字长。定义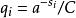 ,其中 C 会使得
,其中 C 会使得 。于是
。于是
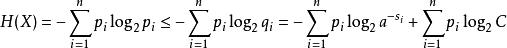
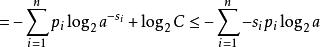

其中第二行由吉布斯不等式推出,而第五行由克拉夫特不等式推出:
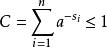
对第二个不等式我们可以令

于是:
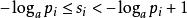
因此
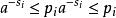
并且
因此由克拉夫特不等式,存在一种有这些字长的无前缀编码。因此最小的 S 满足