置信区间
基本信息
- 中文名
置信区间
- 外文名
Confidence intervals
- 别称
估计区间
- 表达式
Pr(c1<=μ<=c2)=1-α
- 适用领域范围
统计学2、参数统计
- 应用学科
数学、参数统计
基本简介
置信区间是一种常用的区间估计方法,所谓置信区间就是分别以统计量的置信上限和置信下限为上下界构成的区间3。对于一组给定的样本数据,其平均值为μ,标准偏差为σ,则其整体数据的平均值的100(1-α)%置信区间为(μ-Ζα/2σ , μ+Ζα/2σ) ,其中α为非置信水平在正态分布内的覆盖面积 ,Ζα/2即为对应的标准分数1。
对于一组给定的数据,定义 为观测对象,W为所有可能的观测结果,X为实际上的观测值,那么X实际上是一个定义在
为观测对象,W为所有可能的观测结果,X为实际上的观测值,那么X实际上是一个定义在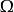 上,值域在W 上的随机变量。这时,置信区间的定义是一对函数u(.) 以及v(.) ,也就是说,对于某个观测值X=
上,值域在W 上的随机变量。这时,置信区间的定义是一对函数u(.) 以及v(.) ,也就是说,对于某个观测值X= ,其置信区间为
,其置信区间为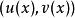 。实际上,若真实值为w,那么置信水平就是概率c:
。实际上,若真实值为w,那么置信水平就是概率c:

其中U=u(X)和 V=v(X)都是统计量(即可观测的随机变量),而置信区间因此也是一个随机区间:(U,V)4。
计算公式
置信区间的计算公式取决于所用到的统计量。置信区间是在预先确定好的显著性水平下计算出来的,显著性水平通常称为α(希腊字母alpha),如前所述,绝大多数情况会将α设为0.05。置信度为(1-α),或者100×(1-α)%。于是,如果α=0.05,那么置信度则是0.95或95%,后一种表示方式更为常用3。置信区间的常用计算方法如下:
Pr(c1<=μ<=c2)=1-α
其中:α是显著性水平(例:0.05或0.10);
Pr表示概率,是单词probablity的缩写;
100%*(1-α)或(1-α)或指置信水平(例如:95%或0.95);
表达方式:interval(c1,c2) - 置信区间。
求解步骤
第一步:求一个样本的均值
第二步:计算出抽样误差。经过实践,通常认为调查:100个样本的抽样误差为±10%;500个样本的抽样误差为±5%;1200个样本时的抽样误差为±3%。
第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点1。
主要性质
较窄的置信区间比较宽的置信区间能提供更多的有关总体参数的信息1。举例说明如下:
假设全班考试的平均分数为65分,则有如下表格中的理解: