数据规格化
基本信息
- 中文名
数据规格化
- 外文名
data normalization
- 所属问题
统计学(数据处理)
- 所属学科
数学
- 方法
标准化、正规化、均值化
- 简介
对数据的规范化处理
基本介绍
有时在试验中,每个标本(样品)有许多种测定值。每种测定值的量纲和数量大小是很不一样的,有的变量的绝对值很大,有的很小,变化幅度很不一样。假如直接用原始数据进行计算,就会突出那些绝对值大的变量,而压低绝对值小的那些变量的作用2。为 了能正确地真正反映实际情况,必须对原始数据进行加工处理,使之规范化。比如,文体竞赛活动中,对于评委所打的分数(原始数据),首先去掉一个 (或两个)最高分,一个(或两个)最低分,然后再求其余分数的算术平均数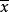 ,以来代表被评者的最后得分, 再去和其他参赛者比较优劣。又如,对原始数据进行标准化处理也是数据规格化的例子。 设有一组数据x1,x2, …,xn,其平均数为,标准差为σ,用公式
,以来代表被评者的最后得分, 再去和其他参赛者比较优劣。又如,对原始数据进行标准化处理也是数据规格化的例子。 设有一组数据x1,x2, …,xn,其平均数为,标准差为σ,用公式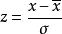 处理后所得的数据z1,z2,…,zn即为标准化数据。可以证明标准化数据z1,z2,…,zn的平均数为 0,标准差为1。因此,对于各个考试科目所得的原始分数,不管平均分和标准差多么的 不同,它们一旦都化成标准分数之后,就都变成了平均数为0,标准差为1的统一固定不变的标准形式。它的大小和正负可以反映某一考分在全体考分中所处的地位。正数为上游,数值越大说明位置越靠前;负数为下游,负数的绝对值越大说明位置越靠下;零分为中游,零分左右靠近中游。将考生各科目的标准分数相加来比较总分的高低以区分考生总成绩的优劣比较合理。再如,归一化处理也是数据规格化的例子。在需要区分各个因素重要性大小的问题中,用原始数据的大小也能看出哪个因素重要,哪个因素次之,哪个因素最不重要。但是对重要程度的表述,既不精确也不规范。为此,可以进行归一化处理: 设原始数据为x1,x2,…,xn,归一化处理后的相应数据为y1,y2,…,yn。两组数据间的关系是式中i=1,2,…,n。可以证明: 对于任一个yi,均有0<yi<1且
处理后所得的数据z1,z2,…,zn即为标准化数据。可以证明标准化数据z1,z2,…,zn的平均数为 0,标准差为1。因此,对于各个考试科目所得的原始分数,不管平均分和标准差多么的 不同,它们一旦都化成标准分数之后,就都变成了平均数为0,标准差为1的统一固定不变的标准形式。它的大小和正负可以反映某一考分在全体考分中所处的地位。正数为上游,数值越大说明位置越靠前;负数为下游,负数的绝对值越大说明位置越靠下;零分为中游,零分左右靠近中游。将考生各科目的标准分数相加来比较总分的高低以区分考生总成绩的优劣比较合理。再如,归一化处理也是数据规格化的例子。在需要区分各个因素重要性大小的问题中,用原始数据的大小也能看出哪个因素重要,哪个因素次之,哪个因素最不重要。但是对重要程度的表述,既不精确也不规范。为此,可以进行归一化处理: 设原始数据为x1,x2,…,xn,归一化处理后的相应数据为y1,y2,…,yn。两组数据间的关系是式中i=1,2,…,n。可以证明: 对于任一个yi,均有0<yi<1且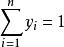 ,yi×100%就是第i个因素在所有因素所组成的总体中的重要程度1。又如聚类分析是根据各变量的观测值予以分类的。它涉及到分析测试等各种手段得来的数据,而这些数据测得的量纲,量级都不尽相同,这就使运算过程中可能突出某些数量级特别大的变量对分类的作用,而压低甚至排除了某些量级很低的变量作用。这样对各变量的分类作用缺乏一个统一尺度。为此,在使用某些数据参加聚类分析计算前,必须对它进行必要的处理或变换,也就是所谓的施行数据规格化,以消除测量单位的分歧,并将每一变量统一于某种共同的数值特征范围。
,yi×100%就是第i个因素在所有因素所组成的总体中的重要程度1。又如聚类分析是根据各变量的观测值予以分类的。它涉及到分析测试等各种手段得来的数据,而这些数据测得的量纲,量级都不尽相同,这就使运算过程中可能突出某些数量级特别大的变量对分类的作用,而压低甚至排除了某些量级很低的变量作用。这样对各变量的分类作用缺乏一个统一尺度。为此,在使用某些数据参加聚类分析计算前,必须对它进行必要的处理或变换,也就是所谓的施行数据规格化,以消除测量单位的分歧,并将每一变量统一于某种共同的数值特征范围。

规格化处理的方法
规格化处理通常的方法有数据的标准化、正规化、均值化及对数变换等3。
数据标准化
设有n个样品,每个样品测量了m项指标(变量),得到如下原始数据矩阵:其中,i为样品个数,j为变量个数。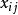 表示第i个样品第j个变量的观测值。设变换后的数据记为
表示第i个样品第j个变量的观测值。设变换后的数据记为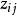 ,则:其中,写成矩阵形式为:则称为
,则:其中,写成矩阵形式为:则称为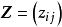 为标准化数据。若所取样品构成的变量服从正态分布,则标准化后的数据
为标准化数据。若所取样品构成的变量服从正态分布,则标准化后的数据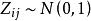 。
。




数据正规化
所谓数据正规化,就是通过极差变换,把原始数据矩阵中的任何一列的最小值化为0,最大值化为1,其余介于0与1之间。记:其中,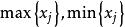 分别为第j个变量的最大值与最小值3。写成矩阵形式为:
分别为第j个变量的最大值与最小值3。写成矩阵形式为:


中心化

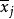 的意义同上。
的意义同上。