lzw算法
基本信息
- 中文名
LZW算法
- 外文名
Lempel-Ziv-Welch Encoding
- 有效期
2003年
- 专利
Unisys
- 简称
LZW 的压缩算法
- 别名
串表压缩算法
LZW算法简介
字符串和编码的对应关系是在压缩过程中动态生成的,并且隐含在压缩数据中,解压的时候根据表来进行恢复,算是一种无损压缩.
根据 Lempel-Ziv-Welch Encoding ,简称 LZW 的压缩算法,用任何一种语言来实现它.
LZW压缩算法的基本概念:LZW压缩有三个重要的对象:数据流(CharStream)、编码流(CodeStream)和编译表(String Table)。在编码时,数据流是输入对象(文本文件的据序列),编码流就是输出对象(经过压缩运算的编码数据);在解码时,编码流则是输入对象,数据流是输出对象;而编译表是在编码和解码时都须要用借助的对象。
字符(Character):最基础的数据元素,在文本文件中就是一个字节,在光栅数据中就是一个像素的颜色在指定的颜色列表中的索引值;
字符串(String):由几个连续的字符组成;
前缀(Prefix):也是一个字符串,不过通常用在另一个字符的前面,而且它的长度可以为0;
根(Root):一个长度的字符串;
编码(Code):一个数字,按照固定长度(编码长度)从编码流中取出,编译表的映射值;图案:一个字符串,按不定长度从数据流中读出,映射到编译表条目.
LZW压缩算法的基本原理:提取原始文本文件数据中的不同字符,基于这些字符创建一个编译表,然后用编译表中的字符的索引来替代原始文本文件数据中的相应字符,减少原始数据大小。看起来和调色板图象的实现原理差不多,但是应该注意到的是,我们这里的编译表不是事先创建好的,而是根据原始文件数据动态创建的,解码时还要从已编码的数据中还原出原来的编译表.
LZW算法
LZW压缩算法

LZW算法基于转换串表(字典)T,将输入字符串映射成定长(通常为12位)的码字。在12位4096种可能的代码中,256个代表单字符,剩下3840给出现的字符串。
LZW字典中的字符串具有前缀性,即 ωK∈T=>;ω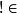 T。
T。
LZW算法流程:
步骤1: 开始时的词典包含所有可能的根(Root),而当前前缀P是空的;步骤2: 当前字符(C) :=字符流中的下一个字符;步骤3: 判断缀-符串P+C是否在词典中(1) 如果“是”:P := P+C // (用C扩展P) ;(2) 如果“否”① 把代表当前前缀P的码字输出到码字流;② 把缀-符串P+C添加到词典;③ 令P := C //(现在的P仅包含一个字符C);步骤4: 判断码字流中是否还有码字要译(1) 如果“是”,就返回到步骤2;(2) 如果“否”① 把代表当前前缀P的码字输出到码字流;② 结束。
LZW解压算法
具体解压步骤如下: